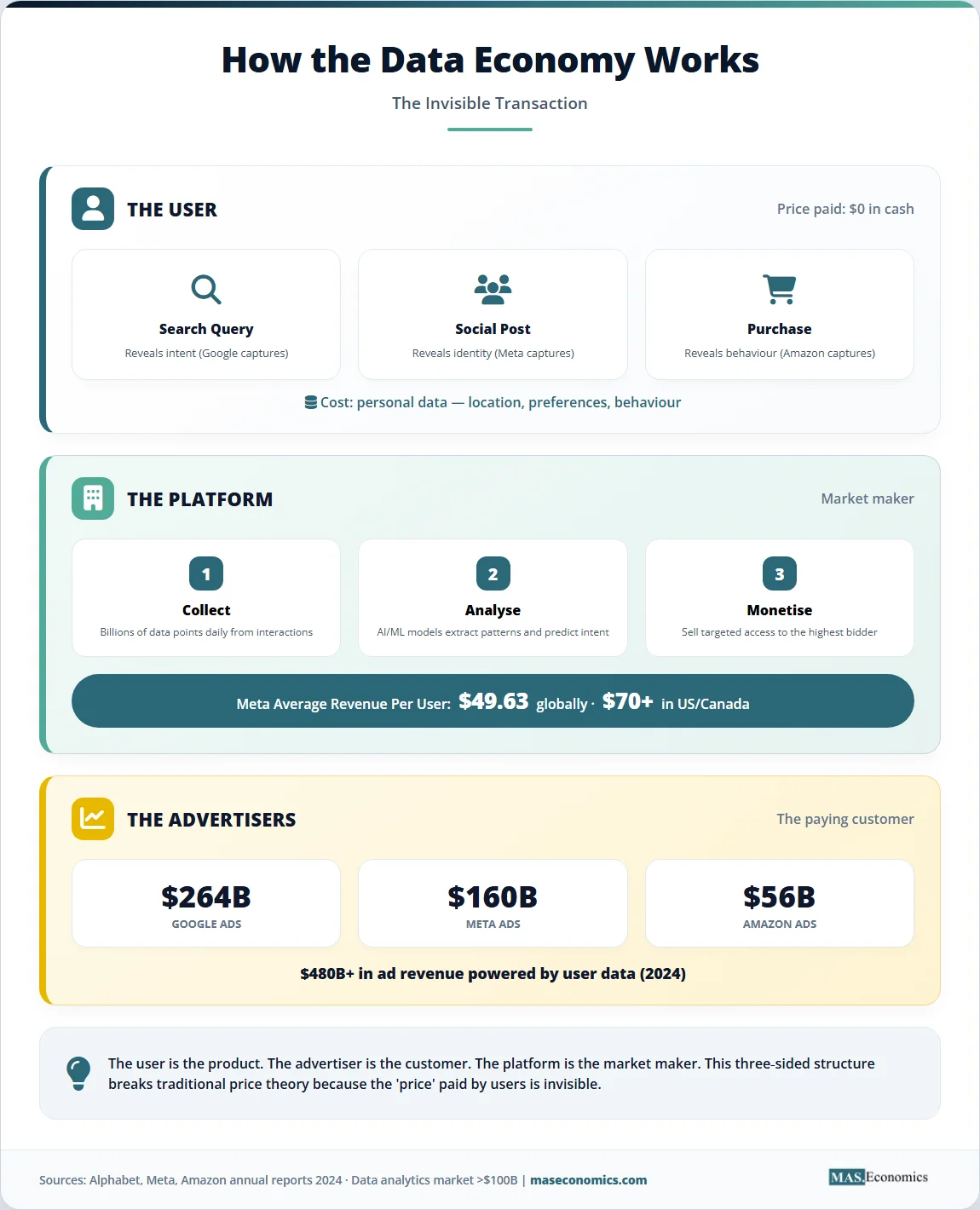
Alphabet earned $350 billion in revenue in 2024, and users never paid a cent. Meta generated $164 billion, with 98% coming from advertising powered by personal data. Amazon’s advertising division alone crossed $56 billion. Combined, these three companies extracted more revenue from data in a single year than the GDP of Portugal. The economics of data is reshaping how markets function, how firms compete, and how governments regulate, because data breaks the most fundamental assumption in traditional economics: scarcity.
Oil must be drilled, refined, and burned. Once consumed, it is gone. Data can be copied infinitely at near-zero marginal cost, used by multiple parties simultaneously, and grows more valuable as it accumulates. A barrel of oil powers one engine. A dataset of one billion consumer profiles powers an advertising algorithm that serves every advertiser on Earth at the same time. This non-rival, non-depletable characteristic makes data unlike any commodity that classical economics was designed to analyse.
By 2026, humanity will generate roughly 221 zettabytes of data per year, equivalent to 402 million terabytes every day. The global data analytics market exceeds $100 billion. The data protection market is valued at $205 billion. The data broker industry, the firms that buy, aggregate, and sell personal information, is projected to reach $656 billion by 2031. Data is not merely valuable. It is the infrastructure upon which the entire digital economy operates.
From Byproduct to Core Asset
Data was once a byproduct of economic activity, an accounting record, a transaction log, a census form. The transformation into a core economic asset began with the commercialisation of the internet in the mid-1990s and accelerated with the smartphone revolution after 2007.
Google’s founding in 1998 marked a critical inflection. The company’s core innovation was not search itself but the discovery that search queries revealed user intent, and that intent could be monetised through targeted advertising. Every search query became a data point. Every click became a signal. By 2003, Google had developed AdWords into a self-service auction platform where advertisers bid in real time for access to users based on their revealed preferences. This model, where the user is the product and the advertiser is the customer, created the economic architecture that would define the next two decades of the digital economy.
Facebook (now Meta) extended the model from intent to identity. While Google knew what users searched for, Facebook knew who they were: their age, location, relationships, political views, interests, group memberships, and emotional states. Meta’s average revenue per user reached $49.63 globally in 2024, rising from $44.60 in 2023. In the United States and Canada, where data is most extensively monetised, ARPU exceeded $70 per user per quarter. Amazon added a third dimension: purchase behaviour. Its advertising business, built on data about what 300 million customers actually buy, grew from near-zero in 2015 to $56 billion in 2024.
The rise of artificial intelligence has intensified data’s economic centrality. Large language models like GPT-4 and Gemini are trained on datasets measured in trillions of tokens. The performance of AI systems is directly correlated with the quantity, quality, and diversity of training data. In the AI era, data has moved from enabling advertising to enabling intelligence itself.
Table 1. The Data Economy: Key Milestones (1998–2026)
| Year | Event | Economic Significance |
|---|---|---|
| 1998 | Google founded; search queries become monetisable data | Established the attention economy: free service in exchange for user data |
| 2004 | Facebook launches; social graph data collection begins | Identity and relationship data become economically valuable for the first time |
| 2007 | iPhone launches; mobile data collection accelerates | Location, app usage, and biometric data enter the commercial data ecosystem |
| 2012 | Obama campaign uses micro-targeted data for voter outreach | Political campaigns adopt commercial data techniques; raises ethical questions |
| 2018 | Cambridge Analytica scandal; EU GDPR takes effect | Public awareness of data exploitation peaks; first comprehensive data regulation |
| 2020 | COVID-19 accelerates digital adoption; data generation surges | Remote work, e-commerce, and telemedicine generate vast new data streams |
| 2023 | ChatGPT launches; AI training data becomes critical resource | Data shifts from advertising fuel to AI training fuel; valuation multiplies |
| 2024 | EU AI Act enters force; US state-level privacy laws proliferate | Regulatory bifurcation: Europe regulates data comprehensively, US fragments |
| 2025–2026 | GDPR cumulative fines exceed €4.5 billion; Meta fined €1.2 billion | Enforcement intensifies; data-as-advertising model faces structural pressure |

|
||
Why Data Breaks Traditional Theory
Data challenges four foundational assumptions of classical and neoclassical economics. Understanding these challenges is essential to grasping why data markets behave so differently from markets for physical goods.
Non-Rivalry and Zero Marginal Cost
In standard economics, most goods are rival: one person’s consumption prevents another’s. Oil burned by one engine cannot power another. Data is fundamentally non-rival. A dataset can be used by an unlimited number of firms simultaneously without diminishing its value. Google’s search data serves millions of advertisers at the same time. Meta’s user profiles power advertising campaigns for Coca-Cola and a local bakery simultaneously, with neither reducing the other’s access.
The marginal cost of reproducing data is effectively zero. Once collected, a dataset can be copied, transmitted, and stored at negligible cost. This zero-marginal-cost structure means that data markets tend toward monopolistic outcomes. The firm with the most data can serve the most advertisers, earn the most revenue, invest the most in data collection infrastructure, and pull further ahead. This is the core mechanism behind the winner-take-all dynamics observed in digital platform markets.
Network Effects and Data Feedback Loops
Data-driven platforms exhibit powerful network effects that traditional markets do not. More users generate more data. More data improves the platform’s algorithms. Better algorithms attract more users. This feedback loop creates self-reinforcing market concentration.
Google’s search algorithm improves with every query processed. Each click teaches the algorithm which results are most relevant, making future searches more accurate, which attracts more users, which generates more data. Meta’s advertising targeting improves with every interaction: every like, share, comment, and scroll duration refines the model’s predictions about user preferences. Amazon’s recommendation engine becomes more effective as its purchase history database grows. These feedback loops function as structural barriers to entry that are more durable than any traditional barrier. A new entrant does not merely need to match the incumbent’s technology. It needs to match the incumbent’s data, which has been accumulating for decades.
Externalities: The Costs Users Do Not See
When a user signs up for a “free” service, a transaction occurs: access to the platform in exchange for personal data. But the full cost of this transaction extends far beyond the individual user. Data collected from one person can be used to infer information about others in their social network, a phenomenon known as data spillovers. Research from the economics of information demonstrates that when one person shares their contacts, location, or preferences, they reveal information about people who never consented to that disclosure.
These negative externalities have measurable consequences. The Cambridge Analytica scandal of 2018 demonstrated how data collected from 270,000 Facebook users was leveraged to build psychographic profiles of 87 million people. The European Union has imposed over €4.5 billion in GDPR fines since 2018, with Meta alone receiving the largest single penalty of €1.2 billion for unlawfully transferring European user data to the United States. Amazon was fined €746 million for targeted advertising conducted without proper consent. These fines represent the regulatory system’s attempt to price the externalities that the market itself fails to internalise.
Market Power and the Attention Economy
The combination of non-rivalry, network effects, and data feedback loops produces extreme market concentration. Alphabet and Meta together capture roughly 50% of global digital advertising revenue. Amazon holds over 35% of the US e-commerce market. These firms do not merely participate in markets. They operate the infrastructure upon which markets function: the search engine, the social network, the marketplace.
This creates a structural problem that conventional antitrust tools struggle to address. In traditional markets, monopoly power is exercised through high prices. In data markets, prices to consumers are zero. The “price” paid by users is their attention and their data, quantities that are invisible in standard economic measurement. A consumer welfare standard calibrated to detect price increases will not register harm when the product is free, but the user’s privacy, autonomy, and informational self-determination are being eroded.
The economic framework of two-sided markets, developed by Jean Tirole (2014 Nobel laureate), helps explain this structure. Platforms serve two distinct groups: users (who pay with data) and advertisers (who pay with money). The platform subsidises one side (free access for users) to attract the other (paying advertisers). This cross-subsidisation model is economically rational but creates a fundamental asymmetry of power: the user has little bargaining leverage because switching costs are high, data portability is limited, and competing platforms with equivalent network effects rarely exist.
The Scale of the Data Economy
The revenue generated by the largest data-driven companies illustrates the economic value of personal information. The chart below compares 2024 revenue for the five companies most dependent on data monetisation.
Revenue of the Largest Data-Driven Companies (2024, $ Billions)
Source: Company annual reports and SEC filings. Alphabet revenue from Q4 2024 earnings. Meta revenue from Meta AI Statistics. Amazon advertising from company filings. ByteDance from Emergen Research projections.
The volume of data generated globally has grown exponentially, and the trajectory shows no sign of slowing. The chart below tracks global data creation from 2010 to 2026.
Global Data Creation (Zettabytes Per Year, 2010–2026)
Source: DemandSage Big Data Statistics 2026 and Statista Global Big Data Market Forecast. 2026 figure is projected.
The regulatory response to data concentration varies dramatically by jurisdiction. The table below compares the three major data governance frameworks and their economic implications.
Table 2. Data Regulation Compared: EU, US, and China
| Dimension | European Union (GDPR + AI Act) | United States | China (PIPL + DSL) |
|---|---|---|---|
| Legal Framework | Comprehensive: GDPR (2018), AI Act (2024), Digital Markets Act (2022) | Fragmented: no federal privacy law; state-level (California CCPA, 19+ states) | State-controlled: Personal Information Protection Law (2021), Data Security Law |
| User Rights | Extensive: right to access, deletion, portability, objection, explanation | Variable by state; no universal federal standard | Strong on paper but subordinate to state security interests |
| Enforcement | Aggressive: €4.5B+ in GDPR fines; Meta fined €1.2B, Amazon €746M | Limited: FTC consent decrees; no dedicated data regulator | Strict: regulators can block data exports and shut platforms |
| Cross-Border Data Flows | Restricted: adequacy decisions required; Schrems II invalidated Privacy Shield | Generally unrestricted within allies; adversary restrictions emerging | Prohibited for sensitive data; security reviews for all outbound transfers |
| Economic Impact | Higher compliance costs; potential innovation drag; stronger consumer trust | Innovation-friendly but growing consumer backlash and state patchwork | State access to data enables industrial policy but deters foreign firms |
|
|
|||
Lessons
Five economic lessons emerge from the first quarter-century of the commercial data economy.
First, non-rivalry changes the competitive dynamics of markets. In physical goods markets, competition tends to reduce prices toward marginal cost. In data markets, where marginal cost is zero, the natural equilibrium is a monopoly or a tight oligopoly. The dominant data platforms are not monopolies because of anti-competitive behaviour alone. They are monopolies because the economic properties of data, its non-rivalry, its network effects, and its feedback loops, structurally favour concentration. Standard antitrust remedies designed for industrial-era monopolies, such as breaking up companies or regulating prices, may not work in markets where the product is free, and the value lies in aggregation.
Second, the absence of property rights over personal data is the central market failure of the data economy. Users generate the raw material. Platforms capture the value. The economic surplus is distributed almost entirely to the platform side of the transaction. The EU’s GDPR represents one model for redressing this imbalance: giving users legal rights over their data. The US has yet to establish a federal equivalent. Until property rights over personal data are clearly defined and enforceable, the data economy will continue to exhibit the characteristics of an uncompensated resource extraction industry.
Third, AI amplifies data’s economic value exponentially. Training data is the core input of every generative AI system. The firms that control the largest, most diverse training datasets, primarily Alphabet, Meta, and Microsoft, hold a structural advantage in the AI race that no amount of algorithmic innovation by smaller competitors can easily overcome. Data scarcity is emerging as a binding constraint on AI development, leading to debates about the legality of scraping publicly available content for model training.
Fourth, the regulatory geography of data is fragmenting. The EU, US, and China have adopted fundamentally different approaches to data governance, creating a tripartite regime that complicates cross-border commerce, AI development, and global value chains. Firms operating across all three jurisdictions must comply with conflicting requirements on data storage, consent, portability, and government access. This fragmentation imposes real costs, particularly on smaller firms that lack the compliance infrastructure of the tech giants.
Fifth, data governance is ultimately a question about power. The economic debate over data, whether it should be treated as a public good, a private asset, or a regulated utility, is inseparable from political questions about surveillance, autonomy, and democratic accountability. The same data infrastructure that enables personalised advertising also enables election manipulation, social scoring, and mass surveillance. The economic framework of information asymmetry helps explain the power imbalance: platforms know everything about users, while users know almost nothing about how their data is collected, processed, or monetised.
MASEconomics Explains
Four economic concepts behind the data economy
Conclusion
The economics of data is the economics of the 21st century. A resource that is non-rival, non-depletable, and infinitely reproducible at zero marginal cost challenges the scarcity-based foundations of classical economic theory. The firms that mastered data collection and monetisation first, Alphabet, Meta, and Amazon, have built market positions that are structurally reinforced by network effects, feedback loops, and the absence of clear property rights over personal information. The regulatory response is fragmented: Europe has chosen comprehensive regulation, the United States remains patchwork, and China has opted for state control. As AI transforms data from an advertising input into the substrate of artificial intelligence, the economic and geopolitical stakes of data governance will only intensify. The central economic question of the data age is not whether data is valuable. It is who owns it, who profits from it, and who bears the costs when it is misused.
Did you find this article helpful? Share it with someone who loves economics. And remember, at MASEconomics, we make complex ideas simple.