
A literature can look convincing even when the evidence base is incomplete. If statistically significant studies are more likely to be written up, submitted, accepted, cited, and remembered, while null results remain unseen, the published record no longer represents the full research process. Publication bias file drawer problems occur when missing studies, especially null or weak results, make an effect appear stronger, cleaner, or more reliable than it really is.
The file drawer problem is the image behind the mechanism. Some studies are visible because they produce publishable results. Others remain in a researcher’s folder, hard drive, thesis appendix, rejected manuscript, or institutional report. The problem is not only that a few papers are missing. It is that the missing papers are often missing for systematic reasons. Results that are surprising, statistically significant, or aligned with a strong narrative are more likely to enter the literature than results that show no effect.
For economics, this matters because published evidence influences policy. Minimum wages, job training, tax enforcement, education interventions, microcredit, inflation expectations, discrimination, health subsidies, and development programs are often judged through published research. If the published literature overrepresents successful or significant findings, policymakers may overestimate how much a policy works, how general the effect is, or how settled the evidence has become.
Published Literature vs Research Universe
Publication bias begins with a simple distinction: the studies that exist are not always the studies that appear in journals. Researchers run projects. Some produce large effects, some small effects, some null effects, and some ambiguous results. The published literature is a selected subset of that larger research universe.
That selection can happen at many points. A researcher may not write up a null result because it seems uninteresting. A seminar audience may respond more strongly to significant findings. A journal may prefer a clear positive result over an imprecise estimate. Reviewers may ask for additional specifications until the result becomes sharper. Editors may worry that a null result will attract fewer citations. Each decision can be understandable on its own. Together, they can distort the evidence base.
Robert Rosenthal’s “file drawer problem” article gave the problem its most memorable name. The central concern was that studies with null results may be hidden away, leaving reviewers to synthesize only the visible studies. Once the missing studies are systematically different from the published studies, a literature review can become biased even if every published paper is accurately reported.
This is why publication bias belongs beside replication crisis economics in the research-methods toolkit. A finding may fail to replicate because the original estimate was noisy, because the setting changed, because the design was weak, or because the visible literature was selected toward significant results. Publication bias is one reason published evidence can look more stable than it is.
File Drawer Selects on Results
The file drawer problem is not simply missing data. Missing studies become a bias problem when the probability of publication depends on the result. If null results are just as likely to be published as significant results, the literature may remain balanced. If null results are much less likely to appear, the published record tilts toward positive findings.
Consider a simple example. Twenty teams study whether a training program raises earnings. Suppose the true effect is small and difficult to estimate. By chance, a few studies produce statistically significant positive effects. Several produce small positive effects. Some produce no effect. One or two produce negative estimates. If the significant positive results are published and the rest remain unpublished, a later reader may conclude that the program clearly works.
The problem grows when the literature is used for synthesis. A meta-analysis combines published estimates to summarize an evidence base. If the included studies are selected toward significance, the combined estimate may be inflated. A precise-looking meta-analytic average can still be biased if the search process misses unpublished or hard-to-find null results.
This is why a systematic literature search matters. A review that includes working papers, trial registries, dissertations, institutional reports, replication archives, and pre-analysis plans is less exposed to file drawer bias than a review that relies only on published journal articles.
Publication Bias vs P‑Hacking
Publication bias and p-hacking often reinforce each other, but they are not the same problem. P-hacking happens inside a study when researchers search across outcomes, samples, controls, transformations, or timing windows until a significant result appears. Publication bias happens across studies when some results are more likely to become visible than others.
The distinction matters because the remedy differs. P-hacking is addressed through pre-specification, transparent code, full outcome reporting, and disciplined analysis plans. Publication bias is addressed through registries, working-paper searches, result-blind review, acceptance of null findings, and meta-analytic methods that test for selection.
A study can be free of p-hacking but still contribute to publication bias if it remains unpublished because the result is null. A literature can also suffer from both problems at once: individual studies search for significance, and then journals select the significant studies for publication. In that case, the visible literature is shaped twice, first by within-study flexibility and then by across-study selection.
For empirical economics, the combined risk is serious because policy debates often lean on bodies of evidence rather than one study. If the literature contains hidden specification search and missing null results, the apparent consensus may be stronger than the underlying evidence.
Incentives for Significant Findings
Economists face professional incentives that can intensify publication bias. A statistically significant finding is easier to summarize, easier to present in a seminar, easier to frame as a contribution, and often easier to publish. A null result may be valuable, but it can be harder to sell unless the design is especially strong or the question is central.
The pressure is not only academic. Policy audiences also prefer clear answers. “The program raised earnings” is easier to communicate than “the estimate is imprecise and consistent with several effects.” Donors, governments, journals, and media often reward clean stories. That does not mean researchers are dishonest. It means the research ecosystem can systematically filter evidence.
Brodeur, Lé, Sangnier, and Zylberberg’s “Star Wars: The Empirics Strike Back” documented patterns in reported test statistics in leading economics journals that are consistent with pressure around conventional significance thresholds. Their evidence does not prove misconduct in any individual paper. It shows why the distribution of published results deserves scrutiny.
Ioannidis, Stanley, and Doucouliagos’ “The Power of Bias in Economics Research” examined credibility issues in empirical economics through the lenses of statistical power and bias. Their work is often cited because it treats publication selection as a field-level problem, not merely a flaw in isolated papers.
Forms of Publication Bias
Publication bias appears in several forms. Some involve the decision to publish at all. Others involve what gets emphasized after publication. The table below separates common mechanisms because each one distorts evidence in a different way.
| Bias mechanism | What becomes visible | What may disappear | Effect on the literature |
|---|---|---|---|
| File drawer | Significant or positive studies | Null or weak results | Average effects look larger |
| Journal selection | Clean, surprising findings | Messy or inconclusive estimates | Evidence looks more decisive |
| Selective reporting | Preferred outcomes or subgroups | Unfavorable specifications | Readers see a partial study |
| Citation bias | Memorable positive findings | Less dramatic null results | Influential reviews become tilted |
| Language or access bias | Easy-to-find published work | Local reports or unpublished studies | Policy synthesis misses context |
| Top-journal bias | High-status significant results | Lower-status replications | Prestige substitutes for coverage |
|
Source: MASEconomics synthesis based on Rosenthal (1979), Stanley (2005), Doucouliagos and Stanley (2009), Brodeur et al. (2016), and Ioannidis, Stanley, and Doucouliagos (2017).

|
|||
The common thread is selection. A biased literature does not require fabricated data. It can emerge from repeated small choices about what is written, submitted, accepted, highlighted, cited, and synthesized.
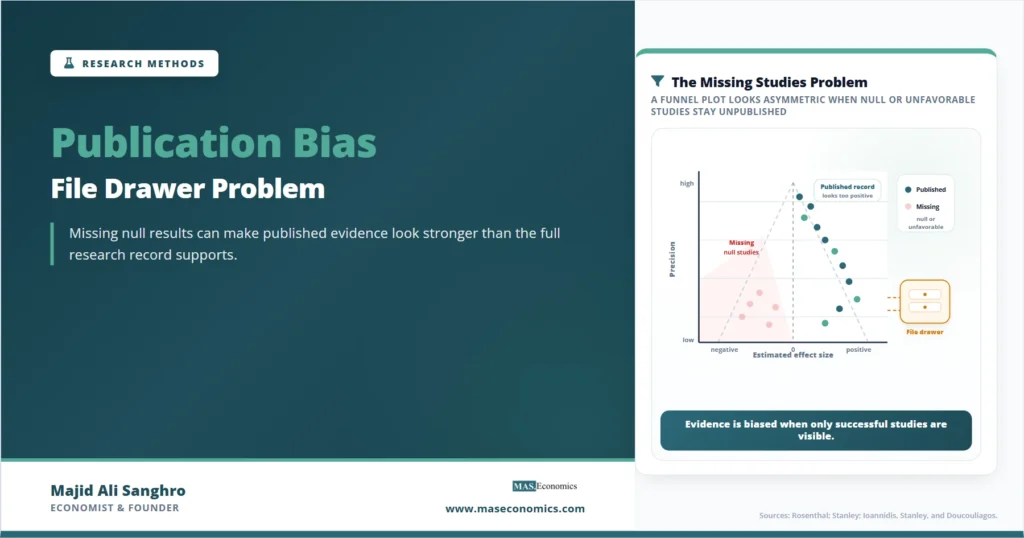
Funnel Plot Diagnostic
A funnel plot is one common diagnostic for publication bias in meta-analysis. The horizontal axis shows the estimated effect. The vertical axis shows study precision or sample size. Large, precise studies should cluster near the true effect. Smaller, less precise studies should scatter more widely on both sides, forming a roughly symmetric funnel when the literature is not strongly selected.
When small studies with null or unfavorable estimates are missing, the funnel becomes asymmetric. That asymmetry does not prove publication bias by itself. Real heterogeneity, design differences, and measurement differences can also create asymmetry. But the plot gives readers a visual way to see whether the published evidence looks balanced.
Meta‑Analysis and Inherited Bias
Meta-analysis is often used to summarize a research literature. It can estimate an average effect, test whether effects vary across settings, and evaluate whether small studies report larger effects than large studies. But meta-analysis is not immune to publication bias. It depends on the studies that can be found.
Stanley’s “Beyond Publication Bias” reviewed graphical and meta-regression methods designed to distinguish genuine empirical effects from publication selection. These tools are useful because they treat the shape of the evidence base as evidence in itself. If smaller and less precise studies report larger effects systematically, readers should ask whether selection is at work.
Doucouliagos and Stanley’s meta-regression analysis of minimum-wage research is a well-known economics example. Their analysis argued that the minimum-wage literature showed signs of publication selection and that correcting for it reduced evidence of a negative employment effect. The broader lesson is not that every minimum-wage result is wrong. It is that a literature can look different after accounting for selection.
The challenge is that publication bias corrections are themselves model-dependent. Different correction methods can produce different adjusted effects. Funnel plot asymmetry can reflect selection, but also real heterogeneity, design differences, measurement quality, or sampling variation. A careful review treats bias diagnostics as evidence to interpret, not as automatic proof.
Null Results as Evidence
A null result is not the same as no information. A well-powered study that finds little effect can narrow the range of plausible policy impacts. A carefully designed null result can show that a popular mechanism is weak, that an intervention does not travel to a new context, or that the expected effect is smaller than policymakers assumed.
Weak null results are different. An underpowered study may fail to detect an effect simply because the sample is too small or the outcome is too noisy. That is why power analysis matters. A null result from a study that could only detect very large effects should not be interpreted as strong evidence of no effect.
The publication system often treats null results as less interesting, but research design should treat them as part of the evidence base. If ten credible studies find no effect and two find large positive effects, the two positive studies should not automatically dominate the conclusion. The pattern itself needs explanation.
For policy, this is critical. Governments and donors need to know not only what works, but also what fails, where it fails, and why. A file drawer full of null results can lead to repeated spending on interventions whose apparent support comes from selective visibility.
Bias Distorts Policy Learning
Economic policy often relies on accumulated evidence rather than one decisive study. A ministry may ask whether training programs raise earnings. A central bank may study communication effects on expectations. A school system may evaluate tutoring or teacher incentives. A development agency may compare health subsidies, cash transfers, or microcredit.
If the published evidence overstates effects, policy learning becomes biased. Programs may be scaled prematurely. Cost-benefit analysis may use inflated effect sizes. Replication failures may appear surprising even though the original literature was selected. Policymakers may underinvest in boring but important null findings.
This connects directly to policy evaluation methods. A strong evaluation design is valuable, but the policy conclusion depends on the full body of evidence. If only successful evaluations appear in the published record, the field can overlearn from success and underlearn from failure.
Publication bias also affects external validity. A program may work in some settings and not others. If only successful settings are published, readers may mistake a conditional effect for a general one. A literature that includes failures is more useful because it reveals boundary conditions.
Study Registries Reduce Invisibility
Registries help reduce publication bias by recording studies before results are known. When a study is registered, later readers can see that it existed even if it never becomes a journal article. This matters because the denominator of research changes. The evidence base is no longer limited to successful publications.
Pre-registration and pre-analysis plans also reduce selective reporting inside published studies. They identify planned hypotheses, outcomes, subgroups, and specifications before outcome data are analyzed. When a published paper differs from its plan, the difference can be explained rather than hidden.
Registries do not solve every problem. A registered study may still be poorly designed, underpowered, or never completed. Researchers may register vague plans. Outcomes may still be selectively emphasized. But registration makes disappearance harder. It creates a record that reviewers, meta-analysts, and readers can use.
For economics, trial registries, replication archives, working-paper repositories, and journal data policies are all part of the same credibility infrastructure. They reduce the gap between the research that was done and the research that becomes visible.
Result‑Blind Review
One structural response to publication bias is result-blind review. Under this model, journals evaluate a study’s question, theory, design, data, and analysis plan before the results are known. If the design is accepted in principle, the journal commits to publishing the study regardless of whether the results are significant, provided the authors follow the approved plan.
Registered reports are one form of this model. They are more common in some fields than in economics, but the logic is relevant. The publication decision shifts from “Did the result look interesting?” to “Was the question important and the design credible?” That directly targets the selection mechanism behind publication bias.
Economics may not adopt one model everywhere. Some studies use administrative data that already exist. Some research is observational and cannot be planned like a trial. Some theoretical or historical work does not fit a registered-report template. Still, the principle travels: journals and reviewers can reward design quality rather than only significant results.
This matters because incentives shape the file drawer. If null results are publishable when the design is strong, researchers have less reason to abandon them. If journals value replication, precision, and transparent uncertainty, the literature becomes less dependent on dramatic findings.
Evaluating the Literature
Readers should not ask only whether a published paper is significant. They should ask whether the literature shows signs of selection. Are null results visible? Are working papers and unpublished studies considered? Are small studies reporting much larger effects than large studies? Are estimates clustered around conventional significance thresholds? Do meta-analyses test for publication selection?
Readers should also look for registries and pre-analysis plans. If a field has many registered studies but only a few published papers, the missing studies matter. If published outcomes differ from registered outcomes, the difference should be explained. If a review excludes gray literature without justification, its conclusions may be too optimistic.
This is part of good systematic literature review practice. A review should define search terms, databases, inclusion rules, exclusion rules, working-paper coverage, and bias diagnostics. Without that transparency, the review itself may reproduce the same selection bias it is trying to summarize.
Readers should also connect publication bias to internal and external validity. A paper can be internally valid in its own setting while the broader literature remains biased. A set of valid studies can still generalize poorly if only successful contexts are visible.
Published Research Value Despite Bias
Publication bias is a warning about selection, not a reason to reject published evidence wholesale. Many published studies are carefully designed, transparent, and important. The problem is that the visible literature can overrepresent a certain kind of result. The right response is better evidence synthesis, not blanket skepticism.
A stronger research culture treats null results, replications, sensitivity analyses, and failed interventions as part of knowledge. It also distinguishes exploratory findings from confirmatory evidence. That distinction improves hypothesis testing because the meaning of a p-value depends partly on how many tests were run, how many studies were attempted, and which results became visible.
Publication bias is easiest to ignore when evidence is summarized as a list of significant findings. It becomes harder to ignore when the research process is visible: study registrations, protocols, data, code, null results, working papers, replications, and meta-analytic diagnostics.
The central lesson is practical. A literature should be judged not only by what it contains, but also by what it may be missing.
Explains
Four concepts behind biased evidence
Build stronger research judgment by learning how evidence is produced, filtered, and synthesized.
Explore the MASEconomics BlogConclusion
Publication bias file drawer problems matter because they separate the published literature from the full research record. When significant, positive, or surprising findings are more likely to become visible, the evidence base can exaggerate effects and understate uncertainty.
The file drawer problem is especially important for economics because research findings shape policy decisions. Missing null results can make programs look more effective, mechanisms look more general, and literature looks more settled than they are. Meta-analysis can help detect the problem, but it can also inherit the bias if unpublished or hard-to-find studies are excluded.
The solution is not to dismiss published research. It is to make the research universe more visible. Registries, pre-analysis plans, working-paper searches, result-blind review, replication archives, and publication of credible null results all reduce the gap between what was studied and what readers see. Better evidence requires not only better estimates, but also a more complete record of the studies behind them.
Frequently Asked Questions
What is publication bias in simple terms?
Publication bias occurs when studies with certain results, especially statistically significant or positive findings, are more likely to be published than studies with null or weak results.
What is the file drawer problem?
The file drawer problem describes studies with null or unfavorable results remaining unpublished or hard to find, leaving the visible literature tilted toward significant findings.
How does publication bias affect economics?
Publication bias can make economic policies, programs, or mechanisms appear more effective than they are if published studies overrepresent significant or positive results.
How is publication bias different from p-hacking?
P-hacking happens within a study when researchers search across choices until significance appears. Publication bias happens across studies when significant results are more likely to become visible.
How can researchers reduce publication bias?
Researchers can reduce publication bias through pre-registration, pre-analysis plans, study registries, result-blind review, replication archives, working-paper searches, and publication of credible null results.
Thanks for reading! If you found this helpful, share it with friends and spread the knowledge. Happy learning with MASEconomics



