
A published economics table may rest on thousands of hidden steps: raw data imports, merges, cleaning decisions, sample restrictions, variable construction, estimation scripts, figure code, and manual notes. Strong replication files reproducibility practice makes those steps visible enough for another researcher to understand, rerun, and evaluate the evidence behind the paper. Replication files are the data, code, documentation, and folder structure that connect a published result to the workflow that produced it.
For economics, this practical distinction matters. Many empirical papers now rely on administrative records, survey microdata, experiments, web data, proprietary datasets, or complex computational pipelines. A coefficient is no longer just a number in a table. It is the final output of a research system. Reproducibility practice asks whether that system is clear enough to inspect.
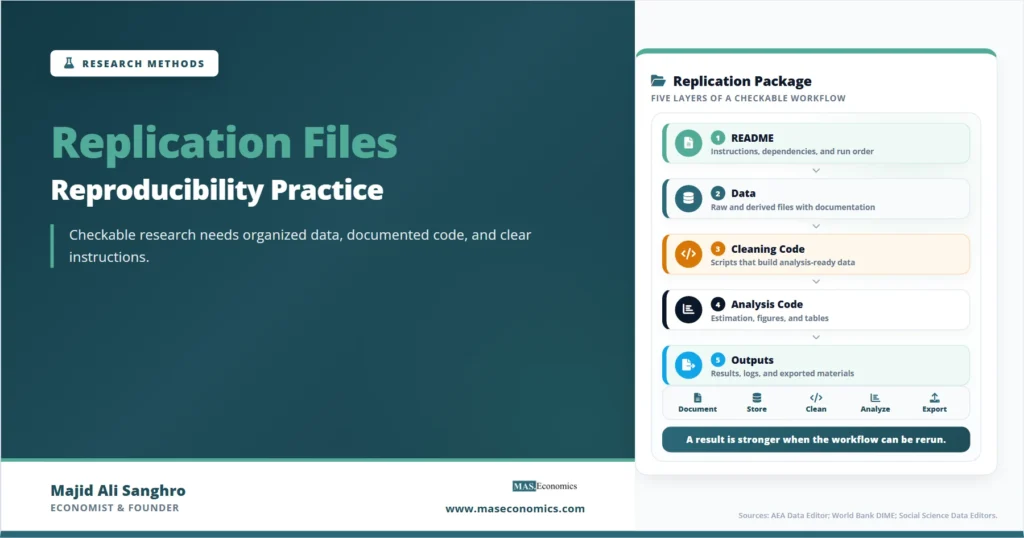
Replication Files as Evidence Trail
A replication file is not one file. It is usually a package. A good package contains the materials needed to regenerate the main tables, figures, and estimates in a paper. It may include raw data when legally shareable, cleaned data, codebooks, cleaning scripts, analysis scripts, output folders, README instructions, logs, metadata, and notes on restricted data.
The purpose is simple. A reader should be able to move from the paper back to the evidence trail. Which dataset was used? How were variables defined? Which observations were excluded? Which code produced Table 2? Which software version was required? Which files cannot be shared, and why?
This makes replication files different from a polished appendix. An appendix explains selected details. A replication package exposes the workflow. It helps readers evaluate whether the result follows from the data and code rather than from undocumented steps.
This practical focus distinguishes the topic from the broader replication crisis in economics. The crisis asks why some findings are fragile. Replication practice asks what authors, journals, and researchers should provide so that published empirical work can be checked.
Reproducibility vs Replication
The words reproducibility and replication are often used loosely. In practice, they refer to different tasks. Reproducibility usually means that another researcher can use the same data and code to obtain the same tables, figures, and estimates. Replication often means testing whether a finding holds with new data, a new sample, a new setting, or a changed design.
Both are valuable, but they answer different questions. If a table cannot be reproduced from the original materials, the paper has a workflow problem. If the table can be reproduced but the finding fails in a new setting, the problem may be external validity, sampling, measurement, context, or theory.
This distinction matters for research judgment. A fully reproducible result is not automatically true. It only means that the computational path from data and code to result can be rerun. The research design may still be weak, the data may be biased, or the identification assumption may fail.
That is why reproducibility belongs next to internal and external validity, not above them. Reproducibility makes the research process inspectable. Validity asks whether the design supports the conclusion.
README as Entry Point
The README is the front door of a replication package. It tells a new user what the project contains, what software is needed, how to run the code, which files are public, which files are restricted, and how the outputs connect to the paper.
A weak README says only “run the code.” A useful README gives the execution order, folder structure, software versions, expected runtime, data access conditions, and output locations. It also explains whether the package reproduces all results or only selected tables because of confidentiality or data-access limits.
The README should also identify the main replication target. If the package reproduces tables and figures in the published article, the README should state which script creates each output. If the paper has online appendix tables, those outputs should be mapped as well. A replication package fails when a reader cannot tell which script produces which result.
The American Economic Association’s Data Editor guidance places preparation of a data and code replication package, including data citations and provenance information, at the start of the process. That is a useful standard because the README should not be assembled as an afterthought. It should grow with the project.
Code Builds the Result
Replication code should do more than sit beside the paper. It should regenerate the result. In a strong workflow, code imports data, constructs variables, applies exclusions, runs analysis, creates tables, produces figures, and saves outputs in predictable locations.
Manual editing is one of the main threats to reproducibility. If a researcher copies numbers into a spreadsheet, adjusts a table by hand, renames columns manually, or edits a figure after export, the final published output may no longer be traceable to code. Small manual changes can become large credibility problems when readers cannot see them.
Good code also separates cleaning from analysis. Cleaning scripts should create analysis-ready data from raw or intermediate data. Analysis scripts should estimate models and produce outputs. This separation makes it easier to diagnose errors. If a coefficient changes, the researcher can ask whether the change came from data construction or the estimation step.
These practices connect directly to data collection in economics. A dataset does not become reliable simply because it appears in a final folder. The research team must show how the data were collected, cleaned, documented, and transformed into variables.
Data Provenance Documentation
Data provenance means the documented history of the data. It tells readers where the data came from, how they were accessed, which version was used, how files were merged, and how variables were constructed. Without provenance, a replication package may reproduce outputs without helping readers understand the measurement process.
Provenance is especially important in economics because many datasets are revised, restricted, linked, or constructed from multiple sources. A paper may combine survey responses, administrative records, regional identifiers, price files, geospatial data, and policy timing. The final analytical dataset may look clean, but the path to it may involve many judgments.
A credible replication package should document raw data sources, download dates where relevant, data citations, file versions, access conditions, and transformations. If the dataset cannot be shared, the author should still explain the source and access procedure clearly enough for readers to understand the limitation.
The AEA’s Data and Code Availability Policy makes this principle institutional. The policy requires authors to provide materials that support reproducibility, subject to data-access and confidentiality limits, and the AEA Data Editor assesses compliance through reproducibility checks.
Replication Standards by Data Type
Not every economics paper can share the same materials. A paper using public census data faces different constraints from a paper using confidential tax records, proprietary firm data, survey microdata, or scraped platform data. The standard should be practical transparency, not careless disclosure.
| Package element | What it should contain | Why it matters | Common weakness |
|---|---|---|---|
| README file | Execution order, software requirements, folder map, output guide | Lets another researcher run and understand the package | Instructions are incomplete or assume author knowledge |
| Data documentation | Source, version, access conditions, citations, variable definitions | Explains data provenance and measurement choices | Final dataset appears without a data history |
| Cleaning scripts | Code that turns raw or intermediate data into analysis data | Makes sample construction and variable creation inspectable | Data were cleaned manually or outside the package |
| Analysis scripts | Code that produces estimates, tables, figures, and appendix outputs | Connects published results to executable commands | Tables require hand editing after code runs |
| Output folder | Generated tables, figures, logs, and comparison files | Shows whether the package reproduces the published paper | Outputs are not named or mapped to the paper |
| Restricted-data note | Explanation of confidential files, access steps, and shareable substitutes | Supports controlled transparency when data cannot be public | Authors only state that data are unavailable |
|
Source: MASEconomics synthesis based on AEA Data and Code Availability Policy, AEA Data Editor guidance, World Bank DIME reproducibility materials, and Social Science Data Editors guidance.

|
|||
The table shows the practical difference between uploading files and producing a reproducible archive. A folder full of code is not enough if no one knows how the files relate to the paper. A public dataset is not enough if variable construction is undocumented. Reproducibility depends on the whole package.
Controlled Transparency for Restricted Data
Economists often work with confidential data: tax records, health records, bank data, school records, firm accounts, household surveys, social-security files, and platform data. These data may be legally or ethically impossible to publish. Reproducibility practice must handle that reality carefully.
Controlled transparency means sharing what can be shared and documenting what cannot. Authors can often share code, metadata, codebooks, variable construction rules, synthetic examples, logs, and detailed access instructions even when the underlying data cannot be posted publicly.
The JEEA Data Editor FAQ describes practical routes for confidential data, such as temporary access for reproducibility checks or remote access to restricted data for a replicator. The specific solution depends on the dataset, but the principle is general: confidentiality should be explained, not hidden behind a vague statement.
This is also an ethics issue. Open data should not expose households, firms, workers, patients, students, or communities to harm. Replication practice should protect privacy while making the analytical path as transparent as possible. That connects reproducibility to ethical economic research.
Caveat. Reproducibility does not require public release of confidential data. It requires clear documentation, shareable code where possible, and a specific explanation of access restrictions.
File Structure for Workflow
A good replication package is organized around the research workflow. The folder structure should make it clear which files are inputs, which files are generated by code, which files are final outputs, and which documents explain the process.
The following stylized file-structure graphic shows one practical template. The exact names can differ across projects, but the logic should remain: document the project, separate raw or restricted inputs from generated files, keep code ordered, and map outputs to the paper.
Logs and Seeds for Audit
Replication is easier when the code leaves a trace. Logs show which commands ran, whether errors occurred, and where outputs were saved. They also help authors diagnose problems before submission.
Random seeds matter when analysis includes simulation, bootstrapping, random assignment checks, machine learning splits, permutation tests, or randomized imputation. Without a fixed seed or a documented randomization procedure, another researcher may get slightly different results even with the same data and code.
Software versions matter as well. A package that runs in one version of Stata, R, Python, Julia, Matlab, or a specialized library may fail or produce small differences in another. Good replication packages report software versions and dependencies clearly.
This is not technical fussiness. It is part of the evidentiary record. When a paper reports a standard error, a bootstrap confidence interval, or a machine-learning prediction, the computational environment can affect reproducibility.
Journal‑Level Reproducibility Checks
Some journals now require data and code before publication. The AEA Data and Code Availability Policy is one important example. AEA journal authors must provide materials that support reproducibility, and the AEA Data Editor evaluates compliance and conducts reproducibility checks.
The AEA Data and Code Repository at ICPSR hosts replication packages for AEA journal articles. Repository archiving matters because files need persistent access, metadata, and preservation. A personal website or temporary folder is not equivalent to a curated repository.
World Bank DIME’s reproducible research guidance provides another useful model. DIME describes computational reproducibility as a requirement for published research outputs and describes verification that de-identified packages reproduce the same results that appear in the paper.
These institutional standards are part of open science infrastructure once that article is live and verified in your inventory. The broader principle is that reproducibility improves when journals, repositories, and research teams treat replication files as part of publication, not as optional extras.
Replication Reduces Hidden Flexibility
Replication files do not eliminate researcher discretion, but they make it more visible. A package can show which sample restrictions were applied, how outliers were handled, how variables were transformed, and which specifications produced the main results.
This matters because hidden analytical choices can alter conclusions. A researcher may choose among outcome definitions, control variables, trimming rules, weighting schemes, imputation methods, and model specifications. When those choices are undocumented, readers cannot tell whether the published result is stable or selected.
Replication practice therefore supports transparency around p-hacking. A full code package does not prove that specification search did not occur, but it lets readers inspect the path from data to result and compare main results with robustness checks.
It also strengthens meta-analysis. When replication materials are available, reviewers can understand definitions, samples, and specifications more accurately. Evidence synthesis improves when each included paper is easier to inspect.
Replication as Student Skill
Replication files are not only for journals and reviewers. They are also a training tool. Students who examine replication packages learn how empirical papers are built: how raw data become variables, how missing values are handled, how tables are generated, and how robustness checks are organized.
This changes the way students read research papers. A paper is not only a written argument. It is a project with a data pipeline. The text explains the claim, while the replication package shows how the claim was computed.
That skill matters for anyone learning hypothesis testing in economics. A p-value or confidence interval is not self-contained. It depends on data construction, sample definition, coding choices, model specification, and output generation.
Replication also teaches humility. Many results depend on ordinary decisions that are easy to miss: how to merge files, whether to keep duplicates, how to define treatment timing, how to treat missing outcomes, and how to label variables. Seeing those steps makes empirical research more concrete.
Common Package Failures
Replication packages often fail for practical reasons. File paths are hard-coded to one computer. Code assumes folders that are not included. Data are missing or renamed. Packages are not listed. The README is vague. Outputs are generated but not mapped to the paper. Figures are edited manually. Restricted-data explanations are incomplete.
Some failures are deeper. The code may not create the analysis dataset from earlier files. The final table may not match the published table. A key variable may appear in the analysis dataset without construction code. A sample restriction may be described in the paper but not implemented in the code. These problems reduce trust even when they do not prove that the result is wrong.
A good replication practice is to test the package on a clean machine or a fresh folder before submission. If the code cannot run outside the author’s original environment, the package is not yet ready.
This is why reproducibility should be built during the project, not after acceptance. Retrofitting documentation at the end is harder and riskier than maintaining a clean workflow from the beginning.
Limits of Reproducibility
A reproducible package can regenerate a table, but it cannot settle every methodological dispute. Readers may still question the research design, the causal assumptions, the measurement choices, the sample, or the interpretation. Reproducibility makes those debates more productive because the materials are visible.
For example, a paper using policy evaluation methods may be computationally reproducible but still vulnerable to spillovers, attrition, weak controls, or external-validity concerns. A reproducible observational study may still depend on unobserved confounding. A reproducible survey study may still contain measurement error.
The correct standard is not “reproducible therefore true.” The standard is “reproducible therefore checkable.” Once a paper is checkable, readers can better separate computational errors from design disagreements.
That distinction keeps this article in the practical standards lane. Replication files are part of credibility infrastructure. They do not replace theory, design, measurement, or judgment.
Pre‑Submission Checklist
Before submitting or resubmitting an empirical paper, authors should test whether the replication package can stand alone. A new user should be able to read the README, install required software or packages, follow the run order, and regenerate the main outputs.
The package should include enough documentation to understand data provenance, variable construction, sample restrictions, and output mapping. If data are restricted, the package should explain access and include all shareable materials. If some results cannot be reproduced externally, that limitation should be stated clearly.
The paper itself should refer to the replication materials where appropriate. Readers should know whether the repository contains the full package, a partial package, a restricted-data workflow, or a public-use substitute.
These expectations also support economic research reports. A research report is stronger when the text, tables, figures, and replication files are aligned. The report claims the result. The package shows how the result was built.
Explains
Four concepts behind reproducible empirical work
Build stronger research judgment by learning how empirical results become checkable evidence.
Explore the MASEconomics BlogConclusion
Replication files reproducibility practice turns empirical economics from a finished table into an inspectable workflow. A good package shows where data came from, how variables were constructed, which code produced the estimates, and how published outputs can be regenerated.
This practice is distinct from the replication crisis. The crisis is a field-level concern about reliability. Replication files are a practical response: better README files, clearer code, documented data provenance, transparent folder structures, output mapping, restricted-data notes, and reproducibility checks.
Reproducibility does not prove that a finding is valid or generalizable. It makes the claim easier to inspect. That is a substantial gain. When economics research affects policy, teaching, and future evidence synthesis, the path from data to result should not be hidden. It should be documented well enough for others to follow.
Frequently Asked Questions
What are replication files in economics?
Replication files are the data, code, documentation, and instructions needed to reproduce the main tables, figures, and estimates in an empirical economics paper.
What should a replication package include?
A replication package should usually include a README, data documentation, cleaning scripts, analysis scripts, output files, software requirements, and notes on restricted data if applicable.
Is reproducibility the same as replication?
No. Reproducibility usually means rerunning the same data and code to obtain the same result. Replication usually tests whether a finding holds with new data, a new setting, or a changed design.
Can a paper be reproducible but still wrong?
Yes. A reproducible paper may still have weak identification, biased data, poor measurement, or limited external validity. Reproducibility makes the workflow checkable, not automatically correct.
How should researchers handle confidential data in replication files?
Researchers should share what can be shared, provide code and documentation where possible, explain access restrictions clearly, and avoid releasing data that could violate privacy or legal agreements.
Thanks for reading! If you found this helpful, share it with friends and spread the knowledge. Happy learning with MASEconomics



