A government can fund a training program, a school can change teacher incentives, or an NGO can subsidize health products, but determining whether the intervention actually changed behavior requires a design that separates causal impact from selection bias. Field experiments economics answers that question by testing policies in real‑world settings while using random assignment to establish causal effects.
A field experiment is not just a survey, not just a regression, and not just a policy pilot. It is a research design in which people, firms, schools, villages, workers, or other real economic units are assigned to treatment and comparison conditions in the field. The setting is natural enough that behavior carries practical meaning, but the assignment mechanism is controlled enough to support causal interpretation.
Random Assignment Creates Comparability
The core logic of a field experiment is simple. Some units are randomly assigned to receive an intervention, and others are randomly assigned to a control or comparison condition. Because assignment is random, the two groups should be similar in expectation before treatment. If outcomes later differ, the difference can be attributed to the intervention, subject to implementation quality and study design.
That makes field experiments different from many observational studies. In a nonexperimental training program, workers who enroll may differ from workers who do not enroll. They may be more motivated, better informed, closer to the program site, or facing different labor-market conditions. A simple comparison of participants and nonparticipants would mix treatment effects with pre-existing differences.
Randomization breaks that link between treatment status and pre-treatment characteristics. It does not guarantee that every realized sample is perfectly balanced, especially in small studies, but it gives researchers a transparent assignment rule. That is why field experiments sit close to the center of modern causal inference.
The basic treatment effect can be written as a difference in average outcomes:
Experimental Treatment Effect
This equation is simple because the design is doing the causal work. The credibility of the estimate comes less from mathematical complexity than from the quality of random assignment, implementation, measurement, and follow-up.
Field Settings Preserve Real Behavior
Laboratory experiments offer tight control, but they often take place in artificial settings. Observational studies use real-world data, but assignment to treatment is usually not controlled. Field experiments occupy the middle ground. They preserve real incentives, institutions, and constraints while introducing random variation into the policy or treatment.
Harrison and List’s “Field Experiments” helped organize the field by showing how experiments vary in naturalness, subject pool, task, stakes, and environment. A field experiment can look like a randomized policy rollout, a correspondence study in labor markets, a pricing experiment, a school-based intervention, a tax-letter trial, or an information experiment.
The field setting matters because economic behavior depends on context. A worker’s job-search response to a reminder may differ from a student’s response to tutoring, a taxpayer’s response to a letter, or a farmer’s response to insurance. Real institutions create frictions that a clean classroom example may miss: paperwork, trust, liquidity constraints, local norms, administrative capacity, monitoring, and competing priorities.
This is why field experiments are especially useful in policy evaluation. They can test whether a program works under actual delivery conditions, not only whether the idea is theoretically appealing.
Landmark Experiments in Applied Economics
Field experiments became influential because they produced clear answers to questions that had been difficult to settle with observational data alone. Some studies tested whether health interventions changed school participation. Others examined discrimination in hiring, teacher incentives, microfinance, tax compliance, or information frictions.
The point of the table below is not that every field experiment should imitate these studies. It is that each study shows a different design problem: spillovers, discrimination measurement, monitoring, take-up, or institutional delivery.
| Study | Economic setting | Design feature | Research lesson |
|---|---|---|---|
| Miguel and Kremer deworming study | School health and education in Kenya | Program phased across schools with spillovers studied | Field experiments must account for externalities |
| Bertrand and Mullainathan resume study | Labor-market discrimination in hiring | Fictitious resumes randomly assigned names | Experiments can isolate discrimination in real markets |
| Duflo, Hanna, and Ryan teacher study | Teacher attendance and incentives in India | Monitoring and pay incentives randomized | Implementation details shape treatment effects |
| Randomized evaluations in development economics | Health, education, credit, agriculture, governance | Policy treatments assigned at individual, school, village, or firm level | Experimental design can test mechanisms, not only average effects |
|
Source: MASEconomics synthesis based on Harrison and List (2004), Miguel and Kremer (2004), Bertrand and Mullainathan (2004), Duflo, Glennerster, and Kremer (2006), and Duflo, Hanna, and Ryan (2012).

|
|||
Miguel and Kremer’s deworming study is often cited because it shows that treatment can affect untreated units through spillovers. Bertrand and Mullainathan’s resume experiment shows how randomization can isolate differential callback rates in a real labor market. Duflo, Hanna, and Ryan’s teacher-incentive experiment shows how monitoring technology and incentive design can change public-service delivery.
Concrete Treatment Definition
A field experiment cannot randomize a vague idea. It must randomize a treatment that can be delivered. That treatment may be cash, information, a reminder, tutoring, price discounts, monitoring, training, access to credit, a default option, a job-market signal, or a program invitation. The research question must be translated into an intervention that field partners can implement consistently.
This practical requirement separates field experiments from purely theoretical research. An economist may want to know whether credit constraints reduce investment, but the experiment must specify the actual treatment: a loan offer, an interest-rate discount, collateral relaxation, a repayment grace period, or financial information. Each version tests a different mechanism.
The treatment also defines the estimand. Offering training is not the same as receiving training. Eligibility is not the same as take-up. Information access is not the same as belief change. A clean study distinguishes assignment, treatment receipt, intermediate behavior, and final outcomes.
This is where pre-analysis plans help. They force researchers to specify the treatment, sample, primary outcomes, subgroup analysis, and estimation strategy before outcome data can influence the design.
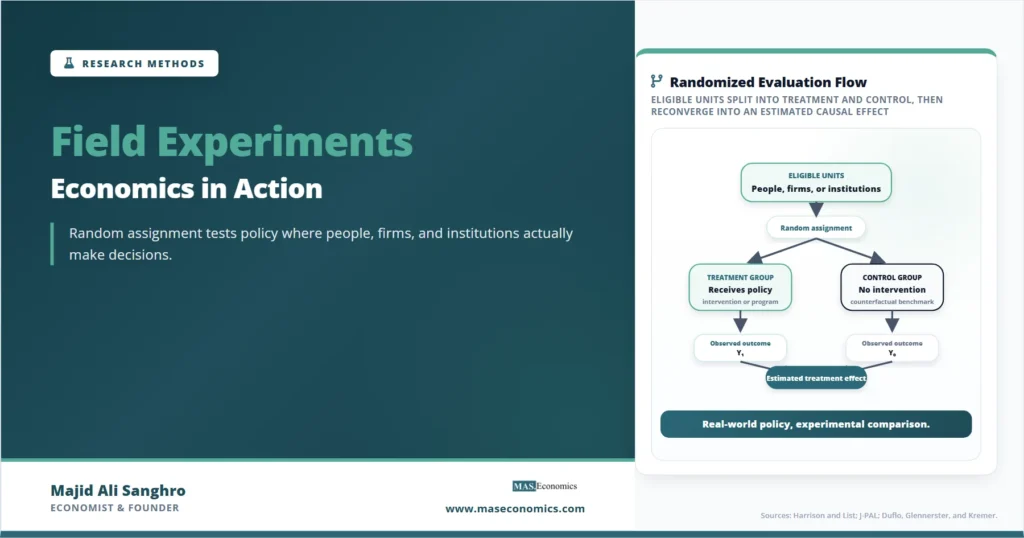
Visualizing the Experimental Design
The following stylized visual shows the basic structure of a field experiment. Random assignment creates two groups before outcomes are observed. The estimated treatment effect comes from the outcome difference after the intervention, not from pre-existing selection into the program.
Implementation Monitoring
In field experiments, the intervention is delivered through real organizations: schools, firms, clinics, local governments, NGOs, tax agencies, banks, platforms, or community groups. Implementation is not a side issue. It determines what treatment actually means.
A tutoring experiment may fail because the curriculum is weak, because tutors are absent, or because students do not attend sessions. A credit experiment may show low impact because few eligible firms take up the offer. A tax-letter experiment may work only when the administrative database is accurate, and the message is delivered at the right time. A job-training experiment may depend on employer connections, instructor quality, and local labor demand.
This is why field experiments require monitoring. Researchers need to track whether the treatment was delivered, whether participants received it, whether control units were protected from accidental exposure, and whether field staff followed the protocol. A weak implementation record makes the causal estimate harder to interpret.
Implementation also affects policy relevance. A treatment that works only when researchers supervise every detail may not work when scaled through ordinary institutions. A field experiment should therefore report not only the estimated effect, but also the delivery conditions that produced it.
Noncompliance and Identification
Random assignment determines who is offered treatment, but people do not always comply. Some assigned to treatment may not participate. Some assigned to control may access similar services elsewhere. Schools may deviate from the protocol. Firms may ignore information. Households may share treatment with neighbors.
This creates a distinction between the effect of assignment and the effect of treatment received. The intention-to-treat effect compares everyone assigned to treatment with everyone assigned to control, regardless of take-up. It answers the policy question: what happens when the program is offered under real take-up conditions?
The treatment-on-the-treated effect tries to estimate the effect among those who actually received the treatment. That can be useful, but it requires additional assumptions because treatment receipt is no longer purely random. People who comply may differ from people who do not comply.
This distinction is closely related to instrumental variables. In some experiments, assignment can serve as an instrument for treatment received. But the interpretation is local: it applies to compliers whose behavior changed because of assignment.
Attrition and Bias
Attrition occurs when researchers lose units after random assignment. Households move. Firms close. Students transfer. Workers stop responding. Some outcomes are missing because participants cannot be found, refuse follow-up, or leave the study area.
Attrition matters because randomization creates comparability at assignment, not automatically at final measurement. If attrition is similar across groups and unrelated to potential outcomes, the risk is lower. If attrition differs by treatment status or by expected outcome, the final sample may no longer be comparable.
For example, a training program may cause unsuccessful participants to migrate for work, making their outcomes harder to measure. A credit program may make surviving firms easier to observe while failed firms disappear. A health intervention may reduce school absence, making treated children easier to find. In each case, missing data may be related to the outcome the experiment is trying to measure.
This connects field experiments to internal validity. A randomized design is internally credible only if the comparison remains valid through implementation, follow-up, and outcome measurement.
Caveat. Random assignment solves selection into treatment at baseline. It does not automatically solve attrition, noncompliance, spillovers, weak measurement, or poor implementation after assignment.
Spillover Effects
Spillovers occur when treatment affects units that were not assigned to treatment. In education, treated students may share information with untreated classmates. In health, treated people may reduce disease transmission to untreated neighbors. In labor markets, training some workers may affect job opportunities for others. In business experiments, treated firms may compete with untreated firms in the same market.
Spillovers can be a problem or a research object. If the goal is to estimate the private effect on treated units, spillovers contaminate the control group and may understate the effect. If the goal is to estimate the social effect, spillovers are part of the policy impact and should be measured.
Cluster randomization is one response. Instead of randomizing individuals within the same school, village, clinic, or market, the researcher randomizes groups. That reduces contamination, though it often requires a larger sample because units inside clusters are correlated.
Spillovers are one reason field experiments sometimes resemble natural experiments in complexity. The assignment rule may be clean, but the economic environment is connected. People interact, information spreads, prices adjust, and institutions respond.
Power and Sample Size
A field experiment may be well designed but too small to answer the question. If the effect is modest, outcomes are noisy, or units are clustered, a small study may produce imprecise estimates. The result may be statistically insignificant even if the treatment has a real effect.
Power analysis helps researchers decide whether the study can detect the effect size that matters for policy. A government may care whether a training program raises earnings by 10 percent, while a researcher may only be able to detect a much larger effect with the available sample. If the minimum detectable effect is too large, the study may not be informative.
Power depends on the number of units, outcome variation, treatment take-up, cluster structure, and baseline controls. Cluster-randomized experiments often need many clusters because individuals within the same school, village, or firm are not statistically independent.
Underpowered experiments contribute to noisy literature. A field experiment should therefore report not only whether the estimated effect is statistically significant, but also whether the design had enough precision to detect meaningful policy effects.
Measurement and Mechanisms
Field experiments can fail at the measurement stage. If the outcome does not capture the relevant mechanism, the estimated treatment effect may be misleading. A health intervention may improve attendance but not test scores. A training program may improve job search but not earnings within the follow-up window. A tax reminder may change payment timing without changing total compliance.
Outcome measurement should match the program theory. If the intervention provides information, the study may need to measure beliefs before behavior changes. If it relaxes liquidity constraints, the study may need to measure investment, cash flow, and repayment. If it changes incentives, the study may need to measure effort, not only final output.
This is where data collection becomes part of experimental design. Administrative records may be precise but narrow. Surveys may capture richer mechanisms but introduce recall error, nonresponse, and measurement error. Field visits may verify implementation but raise costs.
The best field experiments often combine data sources. Administrative outcomes show program participation or payments. Surveys capture behavior and mechanisms. Baseline data help test balance and improve precision. Qualitative field notes explain why implementation succeeded or failed.
Ethics of Randomization
Not every policy question can or should be randomized. Ethical concerns arise when treatment is scarce, potentially harmful, legally required, or politically sensitive. Researchers must consider informed consent, risks to participants, fairness in assignment, privacy, and the consequences of withholding or delaying treatment.
Randomization is often ethically defensible when resources are limited, and not everyone can be served immediately. A lottery or phased rollout may be fairer than informal discretion. But the ethical case depends on the context. A harmful treatment should not be randomized simply to learn its effect. A beneficial treatment with a legal entitlement cannot be withheld casually.
Field experiments also create responsibilities for partner organizations. Researchers must avoid disrupting service delivery, exposing sensitive information, or creating incentives that harm participants. Ethical review is not a box to check after the design is complete. It should shape the design from the beginning.
This connects field experiments to the broader challenge of ethical economic research. Credible evidence should not come at the expense of participant protection.
External Validity
A field experiment can be internally credible and still have limited external validity. A program that works in one city, school system, market, or administrative environment may not work elsewhere. Differences in institutions, prices, norms, infrastructure, teacher quality, labor demand, governance, and baseline conditions can change treatment effects.
This does not make field experiments narrow by default. It means the interpretation should be specific. A deworming program in one setting teaches something about health externalities and schooling, but it does not automatically imply the same effect in every disease environment. A teacher-incentive program in one institutional setting may not generalize to a different school system with different monitoring, pay rules, or political constraints.
External validity improves when experiments are replicated across settings, when mechanisms are measured, and when theory explains why effects should or should not travel. A single field experiment is strongest when it identifies a causal mechanism, not only a local average effect.
This is why field experiments should be read alongside meta-analysis, replication, and theory. Evidence becomes more useful when individual studies accumulate into a pattern.
Theory and Field Experiments
Randomization can tell whether a specific intervention changed an outcome in a specific setting. It does not automatically explain why. Without theory, researchers may test many small variations without understanding the mechanism. Without field evidence, theory may remain detached from implementation constraints.
A strong field experiment begins with a mechanism. Does the intervention change prices, information, incentives, liquidity, trust, attention, bargaining power, or constraints? The treatment, sample, outcome, and timing should follow from that mechanism. When the result arrives, the researcher can then interpret the estimate as evidence about an economic process, not only a program result.
This links field experiments to the scientific method in economics. The experiment tests a claim about behavior. The result then feeds back into theory, policy design, and future research. A null result may be as informative as a positive result if the design was well powered and the mechanism was clearly specified.
The risk is that experiments become a list of isolated program evaluations. The value is greatest when they build cumulative knowledge about behavior, institutions, and policy design.
Researcher Degrees of Freedom
Field experiments can still suffer from specification search. Researchers may test many outcomes, many subgroups, many timing windows, many spillover definitions, or many compliance adjustments. If only significant results are highlighted, randomization does not protect the study from distorted reporting.
This is why experimental economics increasingly emphasizes registration, analysis plans, replication files, and transparent reporting. Random assignment strengthens the design, but it does not remove the need for disciplined analysis.
P-hacking is especially relevant when experiments measure many outcomes. A school intervention may measure attendance, test scores, teacher effort, parental beliefs, aspirations, health, and long-run earnings. A firm intervention may measure sales, profits, employment, investment, productivity, survival, and credit use. The more outcomes tested, the greater the need for clear primary outcomes and multiple-testing discipline.
A field experiment should therefore show the path from design to result. What was randomized? What was pre-specified? What was exploratory? What outcomes were primary? What happened to missing data? How were spillovers handled? These questions determine whether the estimate can be trusted.
Comparing Experimental Designs
Field experiments are one tool in the research-design toolkit. They are powerful when random assignment is feasible, ethical, and relevant. They are less useful when policies have already been implemented, when randomization is impossible, when treatments affect entire systems, or when long-run outcomes take decades to observe.
Regression discontinuity design can be stronger when a real policy cutoff already assigns treatment. Propensity score matching may be useful when only observational data are available, and selection is plausibly captured by observed covariates. Difference-in-differences and synthetic control methods can help when policy changes occur at different times across places.
The advantage of field experiments is control over assignment. The disadvantage is that the experiment must be designed, implemented, funded, monitored, and ethically justified. Many policy questions require a combination of methods: experiments for mechanisms, observational designs for scale, administrative data for long-run outcomes, and qualitative evidence for implementation.
A credible applied economics literature does not rely on one method alone. It uses the design that matches the question.
Explains
Four concepts behind field experiments
Build stronger research designs by connecting real-world policy questions to credible causal evidence.
Explore the MASEconomics BlogConclusion
Field experiments economics matters because it brings causal testing into real economic environments. By randomly assigning interventions in the field, economists can estimate the impact of policies, incentives, information, prices, and institutional changes while observing behavior under practical constraints.
The strength of field experiments comes from random assignment, but credibility also depends on implementation, compliance, follow-up, measurement, spillovers, power, and ethics. A randomized design can still mislead if the treatment is poorly delivered, the control group is contaminated, attrition is selective, or outcomes are chosen after the fact.
The best field experiments do more than ask whether a program worked once. They test an economic mechanism, document the implementation context, and clarify where the result is likely to generalize. When used carefully, they turn policy from guesswork into disciplined evidence. When used casually, they risk giving a weak intervention the appearance of scientific certainty.
Frequently Asked Questions
What is a field experiment in economics?
A field experiment is a study in which real economic units, such as people, firms, schools, or communities, are assigned to treatment and control conditions in a real-world setting.
How is a field experiment different from a lab experiment?
A lab experiment takes place in a controlled artificial setting. A field experiment keeps behavior inside real institutions or markets while using experimental assignment to estimate causal effects.
Why do field experiments use random assignment?
Random assignment makes treatment and control groups comparable before treatment. That helps researchers interpret later outcome differences as effects of the intervention.
What can go wrong in a field experiment?
Common problems include noncompliance, attrition, spillovers, weak implementation, poor outcome measurement, underpowered samples, ethical constraints, and limited external validity.
Can field experiments prove that a policy will work everywhere?
No. A field experiment can provide strong causal evidence in its study setting, but external validity depends on whether institutions, populations, mechanisms, and implementation conditions are similar elsewhere.
Thanks for reading! If you found this helpful, share it with friends and spread the knowledge. Happy learning with MASEconomics